AFu Books Bridge Debian Geocaching IRC Life Notes PostgreSQL Unix
Running Immich on CIFS
Some weeks ago I discovered Immich and was immediately hooked and started feeding the family photo collection into it.
Immich on CIFS
It’s running on a VM at Hetzner, and I immediately filled up the disk with too much data. Looking around, I discovered that Hetzner offers “storage boxes” at the fraction of the cost of a VM with the same disk space, so I launched a 1 TB instance there.
The Immich instance is rooted at /cb/immich/library/. In that directory, Immich confusingly creates another “library” directory, which holds the actual pictures, plus some more subdirectories.
There is now a cifs mount inside the outer library dir:
//u000000-sub1.your-storagebox.de/u000000-sub1 on /cb/immich/library/cifs type cifs
And a bunch of symlinks redirect some of the Immich directories to the remote server:
$ ls -l /cb/immich/library/
insgesamt 12
drwxr-xr-x 2 root root 4096 25. Mär 02:00 backups/
drwxr-xr-x 2 root root 0 2. Apr 18:18 cifs/
lrwxrwxrwx 1 root root 18 24. Mär 19:28 encoded-video -> cifs/encoded-video/
lrwxrwxrwx 1 root root 12 24. Mär 19:28 library -> cifs/library/
drwxr-xr-x 3 root root 4096 23. Mär 13:05 profile/
lrwxrwxrwx 1 root root 11 2. Apr 20:37 thumbs -> cifs/thumbs/
drwxr-xr-x 4 root root 4096 25. Mär 21:54 upload/
Initially I had planned to keep the “thumbs” directory on the local disk for performance, but it outgrew the local disk pretty fast as well. (Perhaps I should move the remaining two over as well…)
It’s not the fastest setup, but it works and the storage space costs are very much ok.
Immich on PostgreSQL
I already have a PostgreSQL instance running, so I didn’t want Immich to create another one. The official documentation mentions this is possible, but doesn’t detail out the instructions. Here’s what I did:
-
In docker-compose.yml, removed the entire
database:section. -
In .env, use these database settings:
DB_PASSWORD=xxxxxxxxxxxx
DB_URL='postgresql://immich:xxxxxxxxxxxx@172.17.0.1/immich'
DB_DATABASE_NAME=immich
(Possibly DB_URL is enough, but the other two don’t hurt.)
- One complication was that the PostgreSQL running outside of Docker needs to
be reachable by Immich inside Docker, so I told it to use the Docker network
address
172.17.0.1. PostgreSQL was already set tolisten_addresses='*', and I just had to add a ufw firewall rule:
sudo ufw allow proto tcp from 172.17.0.0/16 to 0.0.0.0/0 port 5432
And a pg_hba.conf entry:
host all all 172.18.0.0/16 scram-sha-256
By Christoph Berg
read moreSetting up a Minecraft server with mods on a remote Linux box
Information on this is sparse, so here’s a few notes in case I need this again:
To use mods on a Minecraft server, a patched server with a mod loader is required. There are about 4 different ones, but CurseForge seems to be the most popular one.
Go to https://files.minecraftforge.net/ (redirects to https://files.minecraftforge.net/net/minecraftforge/forge/) and download the installer for the desired Minecraft version.
Copy that to the server and run
java -jar forge-1.21.10-60.1.0-installer.jar --installServer .
This creates the directory structure for a Minecraft server. Start it:
./run.sh
On the first run, it will refuse to run. Edit eula.txt and accept the license:
eula=true
If any mods are desired, copy the .jar files into the mods/ folder.
Start it again and configure the whitelist:
screen ./run
[19:36:07] [main/INFO] [cp.mo.mo.Launcher/MODLAUNCHER]: ModLauncher running: args [--launchTarget, forge_server]
[19:36:07] [main/INFO] [cp.mo.mo.Launcher/MODLAUNCHER]: JVM identified as Debian OpenJDK 64-Bit Server VM 25.0.1+8-Debian-1deb13u1
[19:36:07] [main/INFO] [cp.mo.mo.Launcher/MODLAUNCHER]: ModLauncher 10.2.4 starting: java version 25.0.1 by Debian; OS Linux arch aarch64 version 6.12.48+deb13-arm64
...
> whitelist on
> whitelist add swordfish
> op swordfish
[19:37:55] [Server thread/INFO] [minecraft/MinecraftServer]: Made swordfish a server operator
Update: To use “Fabric” instead of Forge, go to https://fabricmc.net/use/server/, and use
java -jar jar
This “downloader” is then also used to launch the server itself with the same command.
By Christoph Berg
read morevcswatch and git --filter
Debian is running a “vcswatch” service that keeps track of the status of all packaging repositories that have a Vcs-Git (and other VCSes) header set and shows which repos might need a package upload to push pending changes out.
Naturally, this is a lot of data and the scratch partition on qa.debian.org had to be expanded several times, up to 300 GB in the last iteration. Attempts to reduce that size using shallow clones (git clone –depth=50) did not result more than a few percent of space saved. Running git gc on all repos helps a bit, but is tedious and as Debian is growing, the repos are still growing both in size and number. I ended up blocking all repos with checkouts larger than a gigabyte, and still the only cure was expanding the disk, or to lower the blocking threshold.
Since we only need a tiny bit of info from the repositories, namely the content of debian/changelog and a few other files from debian/, plus the number of commits since the last tag on the packaging branch, it made sense to try to get the info without fetching a full repo clone. The question if we could grab that solely using the GitLab API at salsa.debian.org was never really answered. But then, in #1032623, Gábor Németh suggested the use of git clone –filter blob:none. As things go, this sat unattended in the bug report for almost a year until the next “disk full” event made me give it a try.
The blob:none filter makes git clone omit all files, fetching only commit and tree information. Any blob (file content) needed at git run time is transparently fetched from the upstream repository, and stored locally. It turned out to be a game-changer. The (largish) repositories I tried it on shrank to 1/100 of the original size.
Poking around I figured we could even do better by using tree:0 as filter. This additionally omits all trees from the git clone, again only fetching the information at run time when needed. Some of the larger repos I tried it on shrank to 1/1000 of their original size.
I deployed the new option on qa.debian.org and scheduled all repositories to fetch a new clone on the next scan:
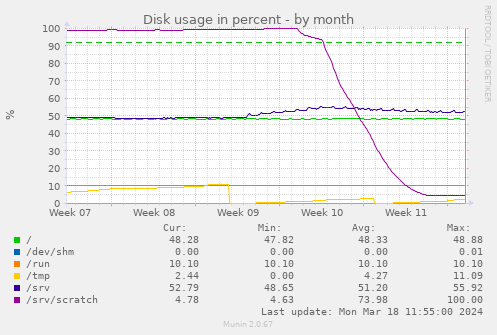
The initial dip from 100% to 95% is my first “what happens if we block repos > 500 MB” attempt. Over the week after that, the git filter clones reduce the overall disk consumption from almost 300 GB to 15 GB, a 1/20. Some repos shrank from GBs to below a MB.
Perhaps I should make all my git clones use one of the filters.
By Christoph Berg
read morePostgreSQL Popularity Contest
Back in 2015, when PostgreSQL 9.5 alpha 1 was released, I had posted the PostgreSQL data from Debian’s popularity contest.
8 years and 8 PostgreSQL releases later, the graph now looks like this:
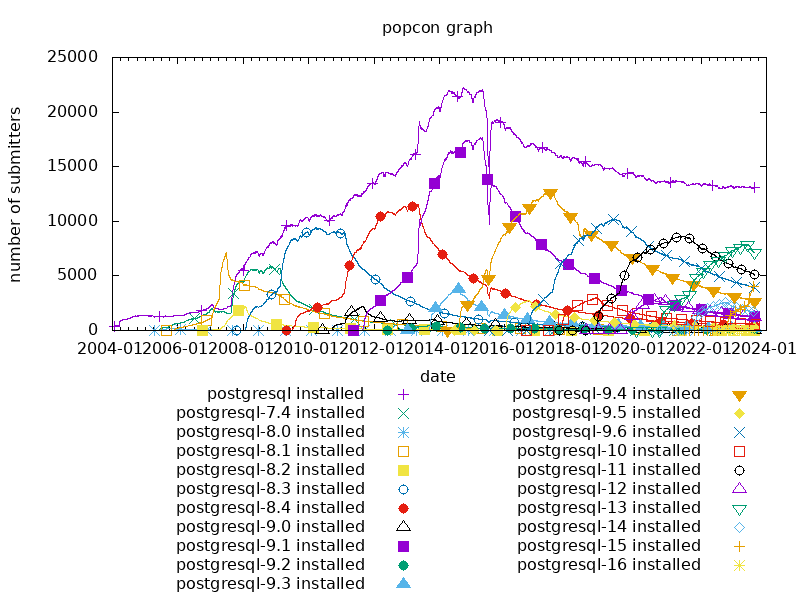
Currently, the most popular PostgreSQL on Debian systems is still PostgreSQL 13 (shipped in Bullseye), followed by PostgreSQL 11 (Buster). At the time of writing, PostgreSQL 9.6 (Stretch) and PostgreSQL 15 (Bookworm) share the third place, with 15 rising quickly.
By Christoph Berg
read moreGetting I/Q SDR data from Icom IC-7610's USB 3 port using libftd3xx
I had been looking around for some time if someone had already managed to get I/Q data from Icom’s IC-7610 HF transceiver without going through the binary-only hdsdr driver provided by Icom, but couldn’t find anything.
First attempts at doing that on Debian Linux using libftdi1 didn’t work, so I resorted to using the (again binary-only) libftd3xx driver from FT, and succeeded after some tinkering around.
The program writes raw I/Q data to a file in int16-int16 format.
- ic7610ftdi: https://github.com/df7cb/ic7610ftdi
- Get libftd3xx from https://ftdichip.com/drivers/d3xx-drivers/
- IC-7610 I/Q port reference: https://www.icomjapan.com/support/manual/1792/
- The IC-7610 needs to be connected using a decent USB 3 cable, preferably without any hub in-between
- If the SuperSpeed-FIFO Bridge disappears after some time, re-plug the cable or power-cycle the transceiver
$ lsusb | grep IC
Bus 002 Device 024: ID 0c26:0029 Prolific Technology Inc. IC-7610 SuperSpeed-FIFO Bridge
$ make
cc -Wall -g -c -o ic7610ftdi.o ic7610ftdi.c
cc ic7610ftdi.o -lftd3xx -o ic7610ftdi
$ ./ic7610ftdi iq.cs16
Device[0]
Flags: 0x4 [USB 3] | Type: 600 | ID: 0x0C260029
SerialNumber=23001123
Description=IC-7610 SuperSpeed-FIFO Bridge
fe fe 98 e0 1a 0b fd ff
fe fe e0 98 1a 0b 00 fd IQ data output: 0
fe fe 98 e0 1a 0b 01 fd
fe fe e0 98 fb fd ff ff OK
RX 42 MiB ^C
fe fe 98 e0 1a 0b 00 fd
fe fe e0 98 fb fd ff ff OK
$ ls -l iq.cs16
-rw-rw-r-- 1 myon myon 44040192 26. Aug 22:37 iq.cs16
$ inspectrum -r 1920000 iq.cs16 &
By Christoph Berg
read moreUDP port forwarding with iptables and ferm
To talk to my IC-7610 via wireguard, I set up UDP port forwarding for ports 50001 50002 50003 on a raspi:
domain (ip) {
table filter {
chain FORWARD {
policy ACCEPT;
}
}
table nat {
chain PREROUTING {
interface (wg0) {
proto udp dport 50001 DNAT to 192.168.0.6;
proto udp dport 50002 DNAT to 192.168.0.6;
proto udp dport 50003 DNAT to 192.168.0.6;
}
}
chain POSTROUTING {
outerface (eth0) {
proto udp dport 50001 SNAT to-source 192.168.0.3;
proto udp dport 50002 SNAT to-source 192.168.0.3;
proto udp dport 50003 SNAT to-source 192.168.0.3;
}
}
}
}
By Christoph Berg
read moreLoRa APRS iGate on TTGO LoRa32
LoRa APRS iGate
The official documentation of https://github.com/lora-aprs/LoRa_APRS_iGate uses the PlatformIO plugin of MS Visual Studio Code. Here are the commands to get it running without the GUI:
git clone https://github.com/lora-aprs/LoRa_APRS_iGate.git
cd LoRa_APRS_iGate
- Edit data/is-cfg.json with your station info
- Edit platformio.ini:
board = ttgo-lora32-v21
pip3 install platformio
pio run
...
Building .pio/build/lora_board/firmware.bin
...
pio run --target upload
...
Uploading .pio/build/lora_board/firmware.bin
...
pio run --target uploadfs
...
Building SPIFFS image from 'data' directory to .pio/build/lora_board/spiffs.bin
/is-cfg.json
...
Uploading .pio/build/lora_board/spiffs.bin
...
LoRa APRS Tracker
The procedure for the tracker is the same, but the GPS module might need a reset first:
git clone https://github.com/lora-aprs/TTGO-T-Beam_GPS-reset.git
cd TTGO-T-Beam_GPS-reset
pio run -e ttgo-t-beam-v1
pio run --target upload -e ttgo-t-beam-v1
# screen /dev/ttyACM0 115200
… and then upload https://github.com/lora-aprs/LoRa_APRS_Tracker.git
By Christoph Berg
read moreIambic CW keyer based on DigiSpark, MIDI, and PulseAudio on Linux
Classic ham radio transceivers have physical connectors for morse keys and microphones. When the transceiver is a software defined radio (SDR) device, voice operation is easy by attaching a headset, but solutions to connect a morse key, be it a straight key or paddles, to a modern PC are rare. In the old times, machines had serial ports with RTS/DTR lines, but these do not exist anymore, so a new interface is needed.
I am using a LimeSDR as ground station for the QO-100 satellite, and naturally also wanted to do CW operation there. I started with SDRangel which has a built-in morse generator, but naturally wanted to connect a CW key. At first sight, all the bits are there, there’s a tune button that could be used as a straight key, as well as keyboard bindings for dots and dashes. But the delay key->local audio is almost a full second, so that’s a no-go. I then went to hack my K3NG keyer to output ^ (high) _ (low) signals on the USB interface, and have a smallish Python program read that and send SDRangel REST API requests. Works, but that solution always felt “too big” to me, plus the sidetone from the buzzer inside the Arduino case could be heard in the whole house. And the total TX-RX delay was well over a second.
Next I tried building some GNU Radio flowcharts to solve the same problem but which all had the same trouble that the buffers grew way too big to allow the sidetone to be used for keying. At the same time, I switched the transceiver from SDRangel to another GR flowchart which reduced the overall TX-RX delay to something much shorter, but the local audio delay was still too slow for CW.
So after some back and forth, I came up with this solution: the external interface from the CW paddles to the PC is a small DigiSpark board programmed to output MIDI signals, and on the (Linux) PC side, there is a Python program listening for MIDI and acting as a iambic CW keyer. The morse dots and dashes are uploaded as “samples” to PulseAudio, where they are played both on the local sidetone channel (usually headphones) and on the audio channel driving the SDR transceiver. There is no delay. :)
DigiSpark hardware
The DigiSpark is a very small embedded computer that can be programmed using the Arduino toolchain.
Of the 6 IO pins, two are used for the USB bus, two connect the dit and dah lines of the CW paddle, one connects to a potentiometer for adjusting the keying speed, and the last one is unconnected in this design, but could be used for keying a physical transceiver. (The onboard LED uses the this pin.)
+---------------+
| P5 o -- 10k potentiometer middle pin
===== Attiny85 P4 o -- USB (internal)
USB ----- P3 o -- USB (internal)
----- P2 o -- dah paddle
===== 78M05 P1 o -- (LED/TRX)
| P0 o -- dit paddle
+---o-o-o-------+
There is an extra 27 kΩ resistor in the ground connection of the potentiometer to keep the P5 voltage > 2.5 V, or else the DigiSpark resets. (This could be changed by blowing some fuses, but is not necessary.)
By Christoph Berg
read morePostgreSQL and Undelete
pg_dirtyread
Earlier this week, I updated pg_dirtyread to work with PostgreSQL 14. pg_dirtyread is a PostgreSQL extension that allows reading “dead” rows from tables, i.e. rows that have already been deleted, or updated. Of course that works only if the table has not been cleaned-up yet by a VACUUM command or autovacuum, which is PostgreSQL’s garbage collection machinery.
Here’s an example of pg_dirtyread in action:
# create table foo (id int, t text);
CREATE TABLE
# insert into foo values (1, 'Doc1');
INSERT 0 1
# insert into foo values (2, 'Doc2');
INSERT 0 1
# insert into foo values (3, 'Doc3');
INSERT 0 1
# select * from foo;
id │ t
────┼──────
1 │ Doc1
2 │ Doc2
3 │ Doc3
(3 rows)
# delete from foo where id < 3;
DELETE 2
# select * from foo;
id │ t
────┼──────
3 │ Doc3
(1 row)
Oops! The first two documents have disappeared.
Now let’s use pg_dirtyread to look at the table:
# create extension pg_dirtyread;
CREATE EXTENSION
# select * from pg_dirtyread('foo') t(id int, t text);
id │ t
────┼──────
1 │ Doc1
2 │ Doc2
3 │ Doc3
All three documents are still there, but only one of them is visible.
pg_dirtyread can also show PostgreSQL’s system colums with the row location and visibility information. For the first two documents, xmax is set, which means the row has been deleted:
# select * from pg_dirtyread('foo') t(ctid tid, xmin xid, xmax xid, id int, t text);
ctid │ xmin │ xmax │ id │ t
───────┼──────┼──────┼────┼──────
(0,1) │ 1577 │ 1580 │ 1 │ Doc1
(0,2) │ 1578 │ 1580 │ 2 │ Doc2
(0,3) │ 1579 │ 0 │ 3 │ Doc3
(3 rows)
Undelete
Caveat: I’m not promising any of the ideas quoted below will actually work in practice. There are a few caveats and a good portion of intricate knowledge about the PostgreSQL internals might be required to succeed properly. Consider consulting your favorite PostgreSQL support channel for advice if you need to recover data on any production system. Don’t try this at work.
I always had plans to extend pg_dirtyread to include some “undelete” command to make deleted rows reappear, but never got around to trying that. But rows can already be restored by using the output of pg_dirtyread itself:
# insert into foo select * from pg_dirtyread('foo') t(id int, t text) where id = 1;
This is not a true “undelete”, though - it just inserts new rows from the data read from the table.
pg_surgery
Enter pg_surgery, which is a new PostgreSQL extension supplied with PostgreSQL 14. It contains two functions to “perform surgery on a damaged relation”. As a side-effect, they can also make delete tuples reappear.
As I discovered now, one of the functions, heap_force_freeze(), works nicely with pg_dirtyread. It takes a list of ctids (row locations) that it marks “frozen”, but at the same time as “not deleted”.
Let’s apply it to our test table, using the ctids that pg_dirtyread can read:
# create extension pg_surgery;
CREATE EXTENSION
# select heap_force_freeze('foo', array_agg(ctid))
from pg_dirtyread('foo') t(ctid tid, xmin xid, xmax xid, id int, t text) where id = 1;
heap_force_freeze
───────────────────
(1 row)
Et voilà, our deleted document is back:
By Christoph Berg
read morearm64 on apt.postgresql.org
The apt.postgresql.org repository has been extended to cover the arm64 architecture.
We had occasionally received user request to add “arm” in the past, but it was never really clear which kind of “arm” made sense to target for PostgreSQL. In terms of Debian architectures, there’s (at least) armel, armhf, and arm64. Furthermore, Raspberry Pis are very popular (and indeed what most users seemed to were asking about), but the raspbian “armhf” port is incompatible with the Debian “armhf” port.
Now that most hardware has moved to 64-bit, it was becoming clear that “arm64” was the way to go. Amit Khandekar made it happen that HUAWEI Cloud Services donated a arm64 build host with enough resources to build the arm64 packages at the same speed as the existing amd64, i386, and ppc64el architectures. A few days later, all the build jobs were done, including passing all test-suites. Very few arm-specific issues were encountered which makes me confident that arm64 is a solid architecture to run PostgreSQL on.
We are targeting Debian buster (stable), bullseye (testing), and sid (unstable), and Ubuntu bionic (18.04) and focal (20.04). To use the arm64 archive, just add the normal sources.list entry:
deb https://apt.postgresql.org/pub/repos/apt buster-pgdg main
Ubuntu focal
At the same time, I’ve added the next Ubuntu LTS release to apt.postgresql.org: focal (20.04). It ships amd64, arm64, and ppc64el binaries.
deb https://apt.postgresql.org/pub/repos/apt focal-pgdg main
Old PostgreSQL versions
Many PostgreSQL extensions are still supporting older server versions that are EOL. For testing these extension, server packages need to be available. I’ve built packages for PostgreSQL 9.2+ on all Debian distributions, and all Ubuntu LTS distributions. 9.1 will follow shortly.
This means people can move to newer base distributions in their .travis.yml, .gitlab-ci.yml, and other CI files.
By Christoph Berg
read more