vcswatch and git --filter
Christoph Berg
Debian is running a “vcswatch” service that keeps track of the status of all packaging repositories that have a Vcs-Git (and other VCSes) header set and shows which repos might need a package upload to push pending changes out.
Naturally, this is a lot of data and the scratch partition on qa.debian.org had to be expanded several times, up to 300 GB in the last iteration. Attempts to reduce that size using shallow clones (git clone –depth=50) did not result more than a few percent of space saved. Running git gc on all repos helps a bit, but is tedious and as Debian is growing, the repos are still growing both in size and number. I ended up blocking all repos with checkouts larger than a gigabyte, and still the only cure was expanding the disk, or to lower the blocking threshold.
Since we only need a tiny bit of info from the repositories, namely the content of debian/changelog and a few other files from debian/, plus the number of commits since the last tag on the packaging branch, it made sense to try to get the info without fetching a full repo clone. The question if we could grab that solely using the GitLab API at salsa.debian.org was never really answered. But then, in #1032623, Gábor Németh suggested the use of git clone –filter blob:none. As things go, this sat unattended in the bug report for almost a year until the next “disk full” event made me give it a try.
The blob:none filter makes git clone omit all files, fetching only commit and tree information. Any blob (file content) needed at git run time is transparently fetched from the upstream repository, and stored locally. It turned out to be a game-changer. The (largish) repositories I tried it on shrank to 1/100 of the original size.
Poking around I figured we could even do better by using tree:0 as filter. This additionally omits all trees from the git clone, again only fetching the information at run time when needed. Some of the larger repos I tried it on shrank to 1/1000 of their original size.
I deployed the new option on qa.debian.org and scheduled all repositories to fetch a new clone on the next scan:
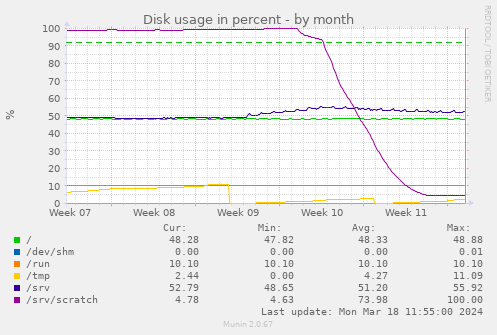
The initial dip from 100% to 95% is my first “what happens if we block repos > 500 MB” attempt. Over the week after that, the git filter clones reduce the overall disk consumption from almost 300 GB to 15 GB, a 1/20. Some repos shrank from GBs to below a MB.
Perhaps I should make all my git clones use one of the filters.